3D Object Detection and Pose Estimation
3D Object Detection and Pose Estimation
1. Problem Description
3D object detection and pose estimation often requires a 3D object model, and even so, it is a difficult problem if the object is heavily occluded in a cluttered scene. In this project, we introduce a novel approach for recognizing and localizing 3D objects based on their appearances through segmentation of 3D surfaces. The approach can identify multiple occluded objects in a scene, which may include different instances of the same object, and estimate the pose of each entire object even if the object can only be seen partially due to occlusion.
2. Surface-based Object Representation
We start from a sufficient number of RGB-D images of different viewpoints of an object (captured by Microsoft Kinect) in order to establish an appearance-based representation of the object. First, images are segmented based on smooth surfaces, where a smooth surface is defined by the continuity of depth and surface normal values, and its boundary is characterized by depth and surface normal discontinuity. Each object is characterized in terms of surface segments from multiple views and the visual signatures of the surface segments. As an example, Fig. 1 shows a common cereal box and its smooth 3D geometric surfaces in terms of the corresponding image segments from different views.
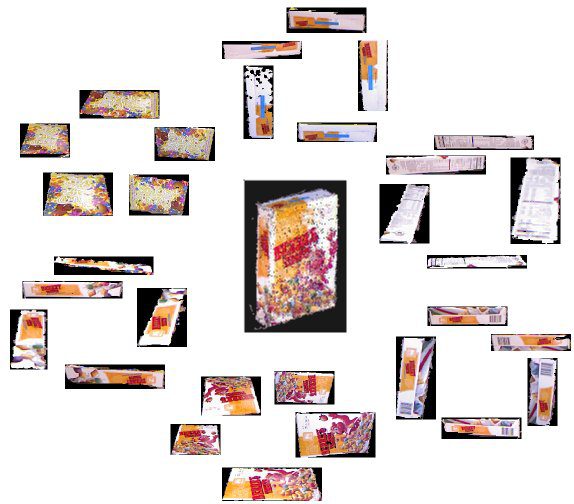
Figure 1: A common cereal box and images of its smooth 3D surfaces from different views
In the representation of an object, after surface segments are obtained from all images of different views, key point matching is then conducted to establish correspondence among surface segments of the same 3D smooth object surface in different images. A coarse 3D model of the entire object is next established based on the matching results, and an object frame (i.e., coordinate system) is specified. This is done by applying SVD and RANSAC algorithms. Fig. 2 shows some reconstruction results.

Figure 2: Examples of reconstructed objects, from left to right: cereal box, cup noodle, milk box 1 and milk box 2
3. Experiments
Fig. 3 shows the results of our approach for object detection and pose estimation for the example test images.  Figure 3: Examples of object detection and pose estimation results: each row starting with an original test image followed by four images from left, back, right, and top views that display the corresponding reconstructed scene. More details can be found in this paper: [1] Zhou Teng and Jing Xiao, “Surface-based general 3D Object Detection and Pose Estimation,” in IEEE International Conference on Robotics and Automation, (ICRA), Hongkong, China, 2014.
Figure 3: Examples of object detection and pose estimation results: each row starting with an original test image followed by four images from left, back, right, and top views that display the corresponding reconstructed scene. More details can be found in this paper: [1] Zhou Teng and Jing Xiao, “Surface-based general 3D Object Detection and Pose Estimation,” in IEEE International Conference on Robotics and Automation, (ICRA), Hongkong, China, 2014.
New Improved Results on Our Own Dataset

Fig. 1: All the reconstructed object models in our current new dataset, including objects with transparent or translucent surfaces (shown in the last column)
Both the training and testing datasets can be downloaded from here.
Fig. 2: Some scene reconstruction results through 3D object detection and pose estimation, shown in the video
More scene reconstruction results are shown in the images as follows: each one starting with an original test image followed by four images from front, left, right, and top views that display the corresponding reconstructed scene.

Fig. 3: scene_1_2

Fig. 4: scene_1_11

Fig. 5: scene_1_12

Fig. 6: scene_2_3

Fig. 7: scene_5_2

Fig. 8: scene_9_1

Fig. 9: scene_9_5

Fig. 10: scene_12_2

Fig. 11: scene_13_3

Fig. 12: scene_13_4

Fig. 13: scene_15_2

Fig. 14: scene_16_2